

Исследовательская группа Tow Center for Digital Journalism изучила ИИ-поисковики и оценила их точность в работе с новостями. Оказалось, что они допускают ошибки в среднем в 60% случаев, а некоторые модели установили антирекорд на отметке 94%
Эксперты изучали восемь поисковых систем с искусственным интеллектом, включая ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search и Copilot.
Исследователи случайным образом выбрали 200 новостных статей от 20 новостных издательств (по 10 от каждого). Затем они выполнили тот же запрос в каждом из инструментов поиска ИИ и оценили точность поиска.
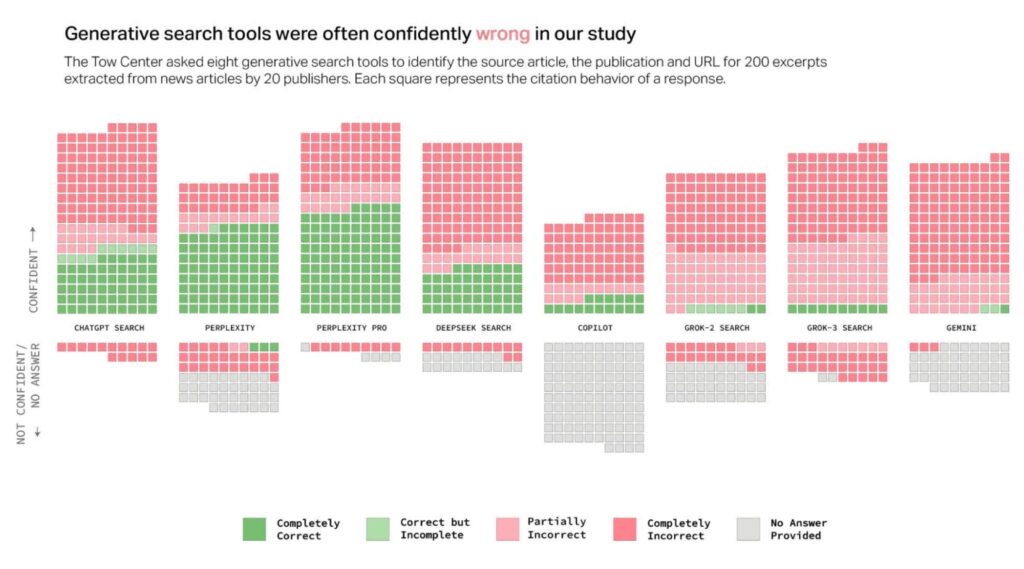
Выяснилось, что в среднем ИИ-поисковики ошибаются в 60% случаев. Более того, ИИ демонстрировал высокую уверенность в своих ошибочных ответах.
Например, даже признав свою неправоту, ChatGPT дополняет это признание новой сфабрикованной информацией. Похоже, что LLM запрограммирован на то, чтобы любой ценой отвечать на каждый запрос пользователя.
Данные исследования подтверждают эту гипотезу: ChatGPT Search был единственным инструментом ИИ, который ответил на все 200 запросов по статьям. Однако его точность составила всего 28%, а доля полностью неверных ответов – 57%. ChatGPT даже не самый худший из всех.
Обе версии ИИ Grok от X показали низкие результаты, а Grok-3 Search ошибался в 94% случаев. Copilot от Microsoft оказался не намного лучше, если учесть, что он отказался отвечать на 104 запроса из 200. Из оставшихся 96 только 16 были «полностью правильными», 14 – «частично правильными» и 66 – «полностью неправильными», что составляет примерно 70% неточностей.


