

На IT-конференции beetech conf Big Data аналитик Бексултан Сагындык рассказал о том, как они с командой создали и выложили в открытый доступ казахскую языковую модель BeeBERT.
Kaz-RoBERTA-conversational (BeeBERT) — это языковая модель, обученная на большом массиве данных на казахском языке, которая была создана разработчиками из Beeline Казахстан. BeeBERT применима к текстовой информации и угадывает, какое слово было пропущено в тексте.
Разработкой языковой модели занималась одна из команд отдела Big data: Бексултан Сагындык, Санжар Мурзахметов, Темирлан Жоламан и Даулет Махметов. Парни рассказывают, что на сбор, обработку данных и дальнейшее обучение модели было потрачено около трёх месяцев.
“Опубликованная языковая модель как таковая не является конечным продуктом, который пользователи могут использовать самостоятельно, но теперь любые разработчики языковых моделей могут внедрить её в чат-боты и системы анализа контента”, – рассказывает Даулет Махметов, менеджер проектов Big Data. Так, в Beeline Казахстан BeeBERT уже позволила увеличить качество распознавания запросов от клиентов в чат-боте на 18%. Дополнительно BeeBERT позволила улучшить возможности автоматического определения языка интерфейса на основании каждого запроса клиента. Например, если один запрос был на русском языке, а другой – на казахском, то, благодаря модели, язык интерфейса чат-бота будет меняться в соответствии с языком запроса.
Помимо этого при доработке (дообучении) BeeBERT сможет переводить, резюмировать и упрощать, а также понимать тональность текстов на казахском языке.
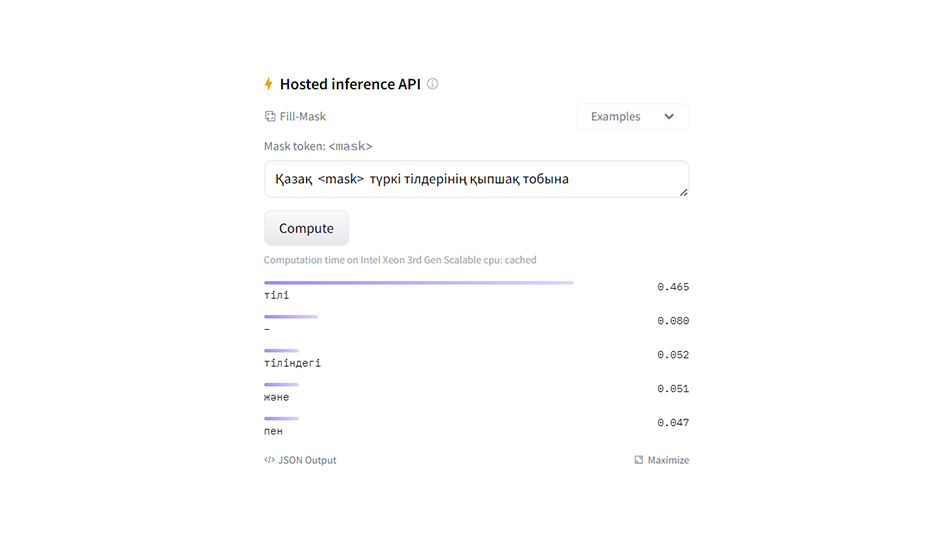
Beeline выложила BeeBERT в открытый доступ на платформе Hugging Face. Это одна из самых популярных площадок для публикации открытых наработок (open source) в области Deep Learning, на которой есть разработки таких компании как Google, Microsoft и тд. Датасет, на котором обучалась данная архитектура, состоит из диалоговых текстов, которые были получены из базы чат-бота Beeline Казахстан, с добавлением обобщенных текстов на казахском языке. Уже сейчас в тестовом режиме любой пользователь может протестировать модель в разделе Hosted inference API. В пустой строке можно ввести предложение на казахском и “спрятать” одно из слов за командой <mask>. Далее при расчете модель показывает слова, которые с большей вероятностью могут стоять вместо <mask>.
Изначально BERT — это нейронная сеть от Google, которая была опубликована в 2018 году в открытом доступе и получила широкое применение во множестве компаний по всему миру.
С момента публикации 6 апреля модель скачали более 45 раз. Подобная публикация модели в открытый доступ – это первый случай среди крупных технологических компаний Казахстана. “Мы надеемся, что этот шаг послужит хорошим примером для других компаний. Опубликовав модель в открытом доступе, мы хотим показать открытость компании и внести свой вклад в развитие языкового и других направлений искусственного интеллекта”, – рассказывают разработчики.

